1997年,国际象棋AI第一次打败顶尖的人类;2006年,人类最后一次打败顶尖的国际象棋AI。欧美传统里的顶级人类智力试金石,在电脑面前终于一败涂地,应了四十多年前计算机科学家的预言。
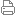
但是,无论人怎么想,这样的局面当然不可能永远延续下去。就在今天,国际顶尖期刊《自然》报道了谷歌研究者开发的新围棋AI。这款名为“阿尔法围棋”(AlphaGo)的人工智能,在没有任何让子的情况下以5:0完胜欧洲冠军,职业围棋二段樊麾。
这是人类历史上,围棋AI第一次在公平比赛中战胜职业选手。
计算围棋是个极其复杂的问题,比国际象棋要困难得多。围棋最大有3^361 种局面,大致的体量是10^170,而已经观测到的宇宙中,原子的数量才10^80。国际象棋最大只有2^155种局面,称为香农数,大致是10^47。 面对任何棋类,一种直观又偷懒的思路是暴力列举所有能赢的方案,这些方案会形成一个树形地图。AI只要根据这个地图下棋就能永远胜利。然而,围棋一盘大约要下150步,每一步有250种可选的下法,所以粗略来说,要是AI用暴力列举所有情况的方式,围棋需要计算250^150种情况,大致是10^360。相对的,国际象棋每盘大约80步,每一步有35种可选下法,所以只要算35^80种情况,大概是10^124。无论如何,枚举所有情况的方法不可行,所以研究者们需要用巧妙的方法来解决问题,他们选择了模仿人类大师的下棋方式。 研究者们祭出了终极杀器——“深度学习”(Deep Learning) 。深度学习是目前人工智能领域中最热门的科目,它能完成笔迹识别,面部识别,驾驶自动汽车,自然语言处理,识别声音,分析生物信息数据等非常复杂的任务。 AlphaGo 的核心是两种不同的深度神经网络。“策略网络”(policy network)和 “值网络”(value network)。它们的任务在于合作“挑选”出那些比较有前途的棋步,抛弃明显的差棋,从而将计算量控制在计算机可以完成的范围里,本质上和人类棋手所做的一样。
| 











 发表于 2016-2-8 21:56:12
发表于 2016-2-8 21:56:12

 收藏
收藏 支持
支持 反对
反对